All big data sets resulting from high-throughput experiments conducted with funding from the National Institutes of Health are deposited in public repositories for researchers to access.

“These data are a treasure trove to reanalyze,” says Katja Koeppen, PhD, a research scientist in the department of Microbiology and Immunology research at the Geisel School of Medicine. She is also the lead data analyst in the DartCF Applied Bioinformatics and Biostatics Core (CF-BBC) that supports scientists with data analysis and bioinformatics.
But, she says, the public repository has limitations; current options to mine publicly available gene expression data deposited in the National Cener for Biotechnology Information gene expression omnibus (GEO), such as the GEO web portal and related applications, are optimized to reanalyze a single study, or search for a single gene, and therefore require manual intervention to reanalyze multiple studies for user-specified gene sets.
Her colleague and manager of the CF-BBC, Tom Hampton, PhD, wanted to make it easier for researchers to identify differentially expressed genes in 20 commonly studied plants, animals, and bacteria.
“He developed a scan that simultaneously looks at differential gene expression of numerous genes across many studies,” Koeppen says. “This was so useful that people in our lab, and other labs at Dartmouth, constantly asked Tom to run scans for them—he was spending so much time doing that he thought it would be great if there was a tool that would allow people to run their own scans.”
Hampton turned to Koeppen to turn his R script, widely used among statisticians and data miners for developing statistical software and data analysis, into a tool for rapid meta-analysis of differential gene expression across GEO datasets.
The result was ScanGEO, a simple, user friendly interactive and interoperable web application that significantly accelerates the analysis of publicly available high-throughput data for hypothesis generation and validation of experimental data. It rapidly mines high-throughput gene expression data to identify genes and pathways of interest to answer biological questions relevant to diverse fields of study. Rather than taking weeks to do this manually, ScanGEO completes the search in minutes.
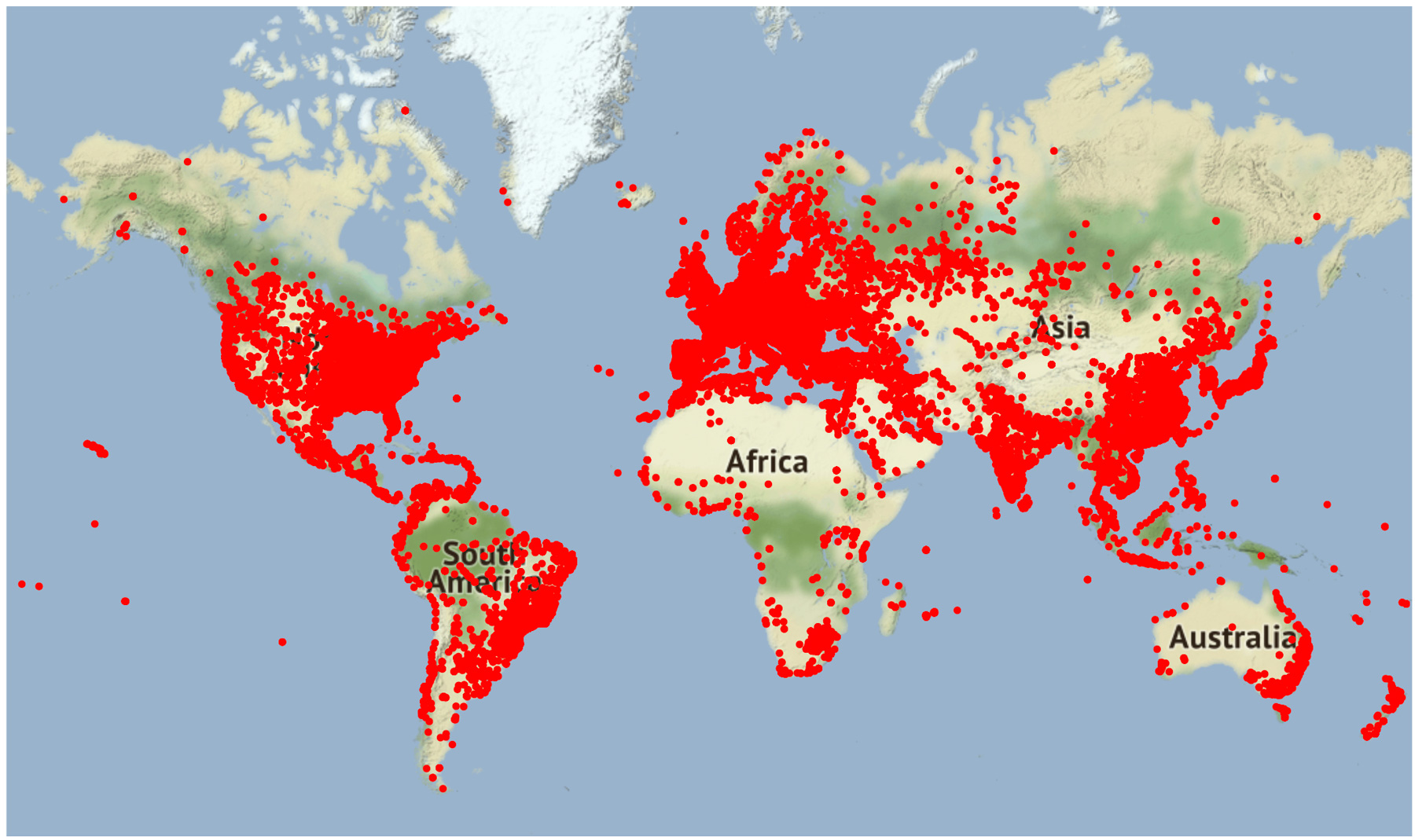
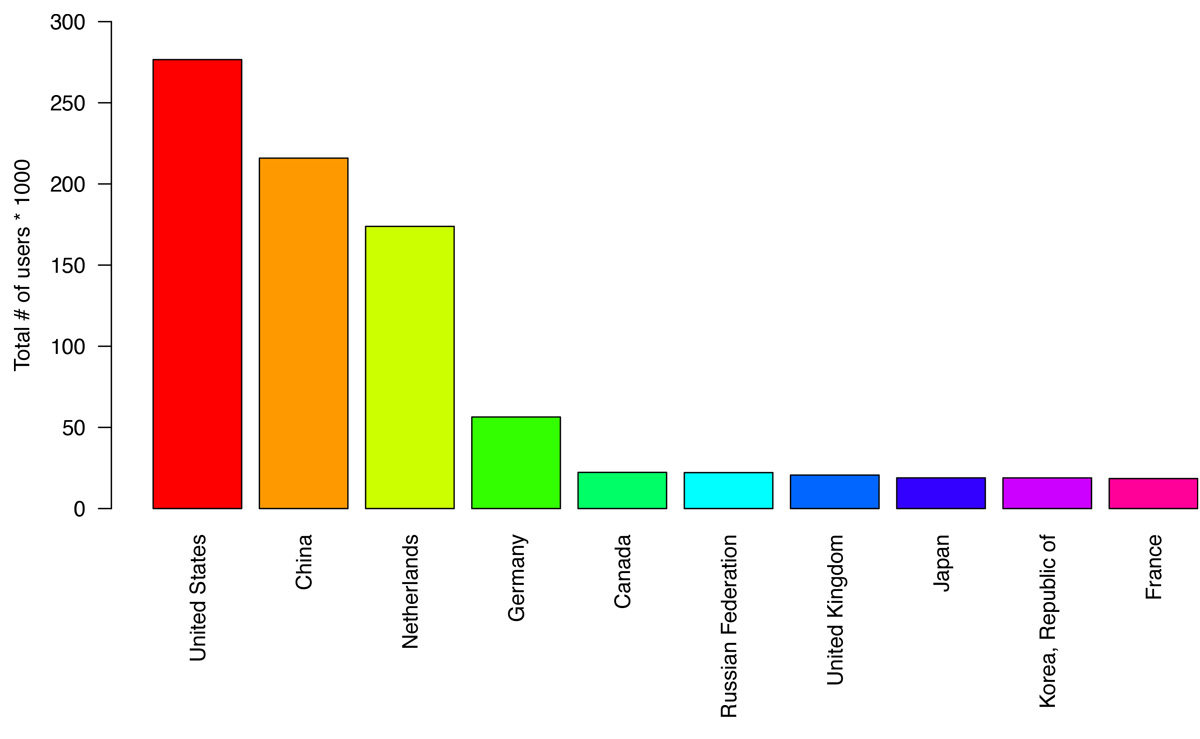
Now four-years old, ScanGEO is heavily used in the U.S., Europe, and China, though Koeppen, who manages the application says, “there is hardly a place in the world where this hasn’t been used—it’s quite amazing given the specificity of the application.”
On average, the worldwide usage per month has been a bit more than 21,000 unique IPs and more than 1 million over the course of four years, but worldwide usage surged when stay-at-home orders incentivized researchers to re-use existing data, Koeppen notes—system access peaked at 120,000 users in March 2020.
“My conclusion is that with labs shut down people were looking for ways to be productive, and one way to do that was to look at existing data and reanalyze it,” she says. “That’s what ScanGEO helps with—it was neat to see it being used this way.”
The CF-BBC, which supports ScanGEO, is directed by Bruce Stanton, PhD, the Andrew C. Vail Professor of Microbiology, and Todd MacKenzie, PhD, professor of biomedical data science, and funded by NIH grant P30-DK117469.